Run GitLab CI long enough and you inherit one of these:
A deploy.sh script nobody wants to touch. A runner with a cluster credential nobody remembers issuing. A kubectl apply someone wrote on a Friday in 2021 and quietly hoped would never break.
The pipeline is in the repo. The trust in it isn’t.
I’ve rebuilt this exact setup three times in the last year. Same lesson every time: the YAML is the easy part. What actually bites in production is four things: the cluster connection, the registry login, the deploy variables that drift between environments, and the multi-team reality of who owns what.
Why three times? Different project, different cluster, same four problems showing up every time. The YAML changed. The hard parts didn’t.
This is the version that finally stuck, the whole thing, copy-paste ready. Take it, adapt the names to your stack, and ship.
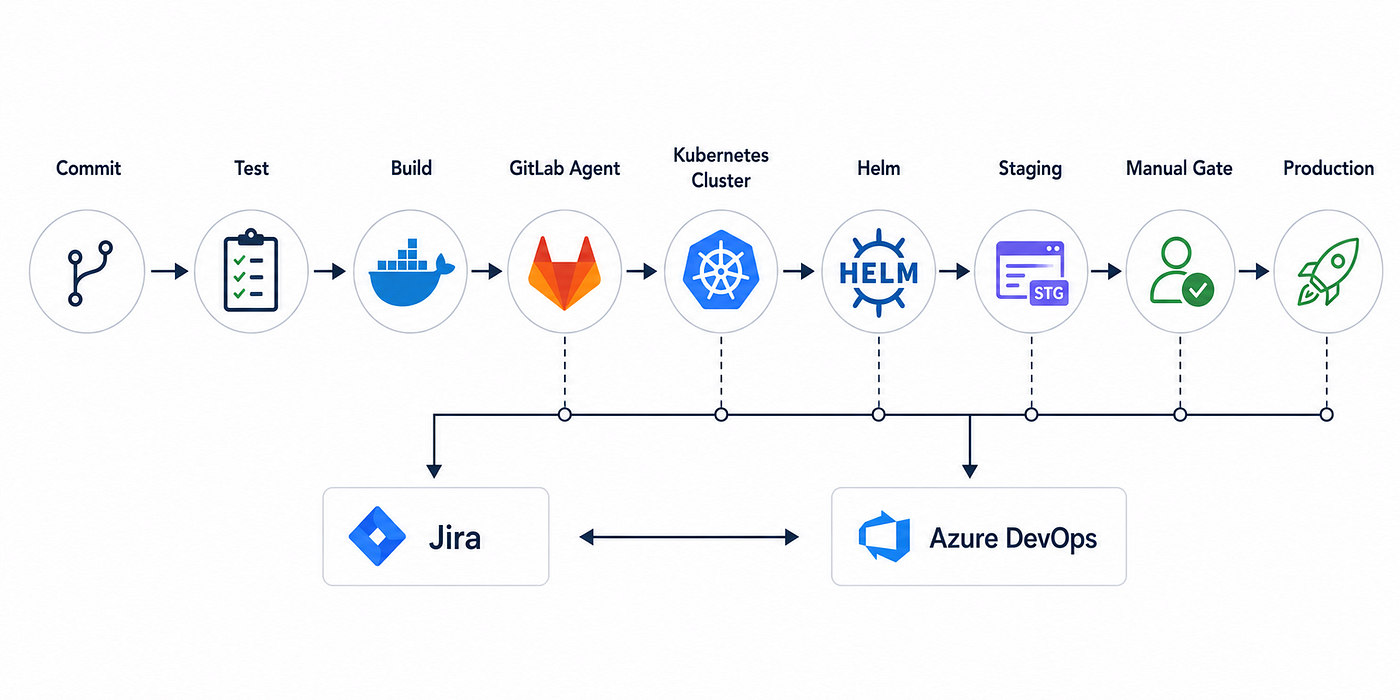
The whole flow in one line: a commit kicks off test, build, and push; the GitLab Agent connects to the cluster; Helm deploys to staging; a human approves; production ships.
What you need first
You’ll need a GitLab project with a Dockerfile at the root (GitLab.com or Self-Managed), a Kubernetes cluster you can already reach with kubectl (EKS, AKS, GKE, k3s, bare metal, it doesn’t matter), a Helm chart for your app, and a GitLab Runner available to the project.
Versions I used: GitLab 19.0, Helm 3, and alpine/k8s:1.34.7 for the deploy job.
Keep kubeconfig out of your CI pipeline
For years the default was dropping a KUBECONFIG into a CI/CD variable. It works. It’s also a long-lived cluster credential sitting in your project settings that nobody rotates, and the first security reviewer with real Kubernetes experience will ask about it.
The GitLab Agent runs inside the cluster and opens an outbound channel to GitLab, so jobs reach the cluster with no stored secret, no inbound firewall holes, and per-project access you actually control.

Drop an agent config into your repo on the default branch at .gitlab/agents/production/config.yaml:
ci_access:
projects:
- id: demo-corp/web-app
environments:
- staging
- production
protected_branches_only: true
access_as:
ci_job: {}
Then register it in the GitLab UI (Operate, then Kubernetes clusters) and install the agent on the cluster with Helm:
helm repo add gitlab https://charts.gitlab.io
helm repo update
helm upgrade --install production gitlab/gitlab-agent \
--namespace gitlab-agent \
--create-namespace \
--set image.tag=<current-agentk-version> \
--set config.token=<your-token> \
--set config.kasAddress=wss://kas.gitlab.com
One thing not to skip: by default the chart gives the agent a cluster-admin service account, which GitLab’s own docs say isn’t suitable for production. Override it with a least-privilege role.
The full pipeline
Here’s the whole .gitlab-ci.yml. Save it at the root of your repo, and I’ll walk through it right after:
stages:
- test
- build
- deploy
default:
image: docker:24.0.5-cli
services:
- docker:24.0.5-dind
variables:
DOCKER_HOST: tcp://docker:2376
DOCKER_TLS_CERTDIR: "/certs"
IMAGE_TAG: $CI_REGISTRY_IMAGE:$CI_COMMIT_REF_SLUG
KUBE_CONTEXT: demo-corp/web-app:production
HELM_RELEASE: web-app
HELM_CHART_PATH: ./charts/web-app
unit-tests:
stage: test
image: node:20-alpine
cache:
key:
files:
- package-lock.json
paths:
- node_modules/
script:
- npm ci
- npm test
build-image:
stage: build
before_script:
- echo "$CI_REGISTRY_PASSWORD" | docker login "$CI_REGISTRY" -u "$CI_REGISTRY_USER" --password-stdin
script:
- docker build --pull -t "$IMAGE_TAG" .
- docker push "$IMAGE_TAG"
rules:
- if: $CI_PIPELINE_SOURCE == "merge_request_event"
- if: $CI_COMMIT_BRANCH == $CI_DEFAULT_BRANCH
deploy-staging:
stage: deploy
image:
name: alpine/k8s:1.34.7
entrypoint: [""]
script:
- kubectl config use-context "$KUBE_CONTEXT"
- helm upgrade --install "$HELM_RELEASE-staging" "$HELM_CHART_PATH"
--namespace staging --create-namespace
--set image.repository="$CI_REGISTRY_IMAGE"
--set image.tag="$CI_COMMIT_REF_SLUG"
--atomic --wait --timeout 5m
environment:
name: staging
url: https://staging.example.com
deployment_tier: staging
rules:
- if: $CI_COMMIT_BRANCH == $CI_DEFAULT_BRANCH
deploy-production:
stage: deploy
image:
name: alpine/k8s:1.34.7
entrypoint: [""]
script:
- kubectl config use-context "$KUBE_CONTEXT"
- helm upgrade --install "$HELM_RELEASE" "$HELM_CHART_PATH"
--namespace production --create-namespace
--set image.repository="$CI_REGISTRY_IMAGE"
--set image.tag="$CI_COMMIT_REF_SLUG"
--atomic --wait --timeout 10m
environment:
name: production
url: https://www.example.com
deployment_tier: production
needs:
- deploy-staging
rules:
- if: $CI_COMMIT_BRANCH == $CI_DEFAULT_BRANCH
when: manual
What each part is doing
Stages and the default image. Three stages: test, build, deploy. The default block sets the Docker-in-Docker image and service every job inherits. Skip DOCKER_HOST and DOCKER_TLS_CERTDIR and the build fails with a TLS error that takes an hour to track down. I’ve spent that hour so you don’t have to.
Build and push. Authenticate to the GitLab Container Registry through stdin, never on the command line where it leaks into process listings. Tag with the commit ref slug, not the ref name, because branch names with slashes are illegal in image tags. Re-pull the base image so a stale layer on the runner can’t bite you.
Deploy with Helm and the agent. Because the agent authorized this project, GitLab mounts a kubeconfig in the job automatically, and kubectl picks the right context. Then an atomic Helm upgrade that waits and times out makes the deploy idempotent and self-healing: a failed rollout rolls itself back instead of leaving half a release live.
Environments and the manual gate. Staging deploys automatically on the default branch. Production sits behind a manual gate and needs staging to have deployed first, so it can’t ship unless staging worked and a human clicks to release. Two seconds of friction, a real audit trail, a lot fewer 3am incidents.
Scaling beyond one team
A few things stay reliable once more teams join the same project. Mark production secrets as protected and masked, and scope them to the production environment. Use include and extends to reuse shared pipeline fragments instead of duplicating YAML, and pin those templates to a tag, never to main. Adopt self-hosted runners once build times or compliance make the shared ones impractical; the Kubernetes executor gives you autoscaling on capacity you already pay for. And keep the real logic in shell scripts rather than YAML, so the YAML stays wiring, not logic.
The part nobody writes about: keeping teams in sync
Engineering lives in GitLab. Product lives in Jira. QA often lives in Azure DevOps. The status of one release ends up scattered across all three, and somebody plays detective every two weeks to write the release notes.
The fix isn’t nagging engineers to update tickets. It’s syncing code state to the work trackers automatically, so a merge or a deploy moves the ticket on its own. That’s the gap an integration platform like Getint fills.
Where I’d take it next: GitOps
Move to GitOps with Flux: it’s GitLab’s recommended production workflow, pull-based, no push credentials, and the agent you just installed already supports it. Add a second cluster with one agent per cluster and a distinct context per environment. Autoscale the runners with the Kubernetes executor. And keep the Helm chart simple, most teams over-engineer it in year one and pay for it in year two.
I originally published a full version of this guide on the Getint blog. Want more hands-on Kubernetes, DevOps and AI? 👉 Follow me here on Medium and let’s connect on LinkedIn!