We’re now in 2026, and I’m starting the year with a small but meaningful milestone: I just reached 300 followers on Medium! 🥳

Photo by Erwan Hesry on Unsplash
To say thank you to everyone who reads and supports my posts, I wanted to give something back… Over the last months, many of you have asked the same thing:
“Can you explain, step by step, how you built your media server with the *arr stack?”
This series is my answer.
This first post is about understanding the system before configuring anything.
⚠️ Disclaimer
This guide is for educational purposes only. Only download content you have the legal right to access. Respect copyright laws in your jurisdiction. The author takes no responsibility for how this information is used.
What This Guide Is About (and What the *Arr Stack Solves)
This is a practical guide to building a fully automated media server using the *arr ecosystem, running on Kubernetes.
The *arr stack is a set of small tools that work together to automate everything around media management. Instead of manually searching, downloading, renaming files, adding subtitles, and importing content into a media server, you define the rules once and let the system do the rest.
The result is simple:
You request a movie, go make a coffee, and when you come back it’s ready to watch.
The Stack
These are the tools that make it work and that I’ll cover throughout the series.
Media & Automation
- Radarr: Manages movies, monitors, grabs, renames, and organizes
- Jackett: Indexer manager that searches torrent sites and integrates with Radarr
- qBittorrent: Download client that handles the actual downloads
- Bazarr: Subtitle manager that automatically finds and downloads subtitles
- Jellyfin: Streams your content to any device
- Jellyseerr: Lets users request movies and shows, like an open-source Netflix connected to Jellyfin
Networking & Access
- Cilium + Gateway API: HTTP routing and clean domains
- AdGuard Home: DNS, ad blocking, and
.homelabdomains - Tailscale: secure access from anywhere, no open ports
Each tool has a clear responsibility. Together, they form a pipeline.
How the System Actually Works
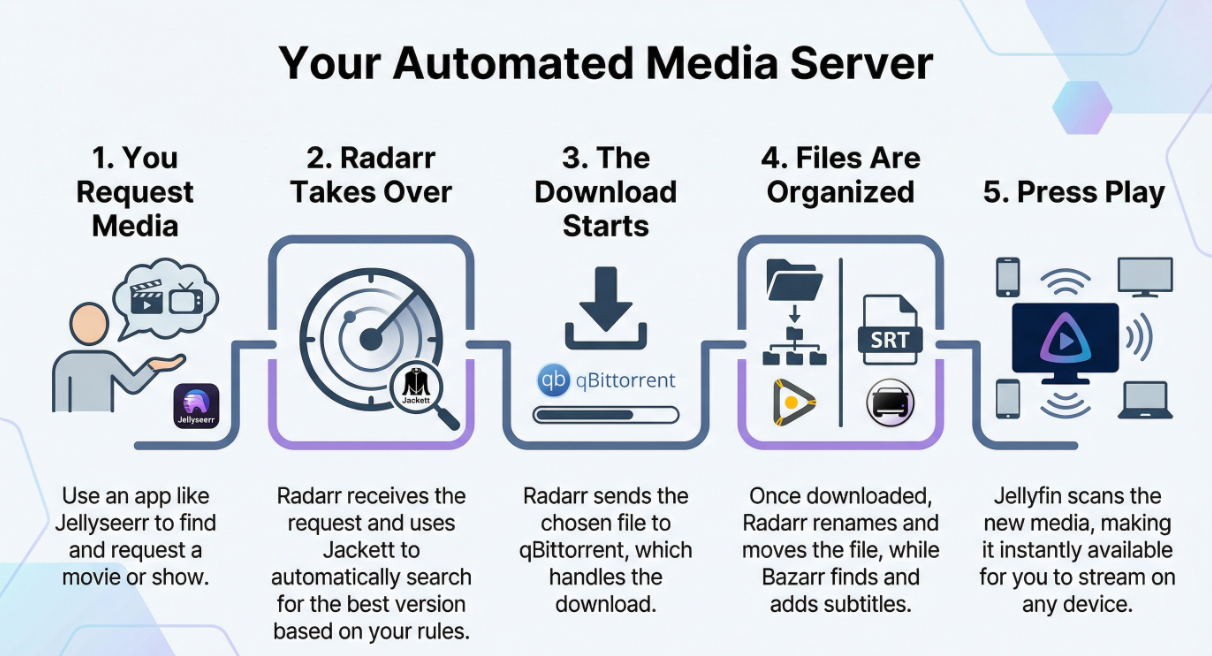
Let’s walk through a real example.
You’re on your phone and want to watch a movie.
- You request it in Jellyseerr
- Radarr receives the request and decides what to download
- Jackett searches indexers and returns results
- Radarr picks the best option based on your rules
- qBittorrent downloads the file
- Radarr renames and moves it into the media library
- Bazarr downloads subtitles
- Jellyfin scans the library
- You press play 🍿
No manual steps.
How This Series Is Organized
I’ll publish this guide in four parts:
- Part 0— Architecture overview (this post)
- Part 1— Radarr, Jackett & qBittorrent (automation and downloads)
- Part 2— Jellyfin, Jellyseerr & Bazarr (streaming, requests, subtitles)
- Part 3 — AdGuard Home, Gateway API & Tailscale (domains and remote access)
Each post builds on the previous one.
See you in the next post 🚀
Thanks again for reading, and for being part of this journey.
Want more hands‑on tips about Kubernetes, Cloud, and DevOps?
👉 Follow me here on Medium and let’s connect on LinkedIn!